
Wir gehen ein komplettes Beispiel zur Normalisierung einer relationalen Datenbank durch in der einhundertvierundvierzigsten Episode des Anwendungsentwickler-Podcasts.
Podcast: Play in new window | Download (Duration: 1:01:52 — 28.8MB)
Abonnieren: Apple Podcasts | Spotify | RSS

Inhalt
Theoretische Grundlagen
- Wir normalisieren Datenbanken um Redundanzen zu vermeiden, die zu Anomalien führen können. Mehr dazu in Podcast-Episode 18.
- Grundlagen wie Schlüssel, Kardinalitäten usw. erkläre ich in Podcast-Episode 17.
- Merksatz: „The key, the whole key, and nothing but the key.“
Beispieldaten
Wir verwenden ein „klassisches“ Beispiel, das so oder ähnlich in vielen IHK-Prüfungen genutzt wird.
- Umfeld: Kunden bestellen Artikel aus verschiedenen Artikelgruppen.
- Ein Kunde kann mehrere Bestellungen durchführen. Eine Bestellung wird immer von genau einem Kunden getätigt.
- Zu den Kunden werden Name und Adresse erfasst.
- Jede Bestellung hat ein Bestelldatum.
- In einer Bestellung können mehrere Artikel enthalten sein. Ein Artikel kann auch in mehreren Bestellungen auftauchen.
- Artikel haben eine Bezeichnung und einen Preis.
- Ein Artikel kann zu genau einer Artikelgruppe gehören. Eine Artikelgruppe kann mehrere Artikel enthalten.
- Artikelgruppen haben eine Bezeichnung und einen Rabatt.
Ausgangssituation (nicht normalisiert)
- Alle Bestellungen stehen in einer einzelnen Tabelle. Jede Bestellung steht komplett inkl. mehrerer Artikel in einer Zeile. Die Adresse steht komplett in einem einzigen Attribut.
- Beispiele für Probleme: Viele Redundanzen (z.B. Adressen, Artikelbezeichnungen), Sortierung nach Ort ist nicht möglich, Selektion aller gekaufter Fernseher ist nicht möglich.

1. Normalform
- Definition: Es gibt 1) nur atomare Attribute und 2) keine Wiederholungsgruppen.
- „the key“: Alle Datensätze sind eindeutig über einen Primärschlüssel identifizierbar.
- Durch 2) werden Redundanzen zunächst eingeführt, da aus einer Zeile nun mehrere Zeilen mit redundanten Inhalten werden.
- Vorgehen: Nicht-atomare Attribute auf mehrere Spalten aufteilen. Wiederholungsgruppen auf mehrere Zeilen aufteilen.
- Ein Datensatz ist über einen zusammengesetzten Schlüssel aus drei Attributen identifizierbar.
- Redundanzen: Kunden-, Bestell- und Artikeldaten sind jeweils mehrfach vorhanden.
- Ursache: Tabelle enthält drei Konzepte (
Kunde,Bestellung,Artikel), die alle nur von Teilen des Schlüssels abhängen und nicht vom gesamten.

2. Normalform
- Definition: (1. Normalform erfüllt und) alle Attribute sind voll funktional vom Primärschlüssel abhängig.
- „the whole key“: Alle Attribute hängen vom gesamten Schlüssel ab (und nicht nur von seinen Teilen).
- Vorgehen: Alle drei Konzepte auf einzelne Tabellen aufteilen. Fremdschlüssel für Referenzen einführen. Zuordnungstabelle
Positionmit zusammengesetztem Schlüssel aus Fremdschlüsseln einführen. - m:n-Beziehungen werden aufgelöst.
Mengegehört an die Kombination ausBestellungundArtikelund weder an das eine noch das andere allein.- Redundanzen:
ArtikelgruppeundRabattgehören zusammen und sind mehrfach vorhanden. - Ursache:
Rabatthängt vonArtikelgruppeab und nicht von derArtikelnummer(=transitive Abhängigkeit).
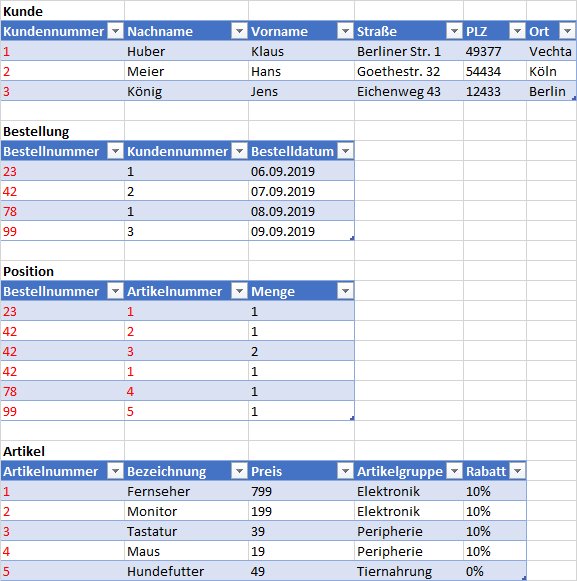
3. Normalform
- Definition: (2. Normalform erfüllt und) es gibt keine transitiven Abhängigkeiten.
- „and nothing but the key“: Kein Nicht-Schlüssel-Attribut hängt von einem anderen Nicht-Schlüssel-Attribut ab.
- Vorgehen:
Artikelgruppein eigene Tabelle extrahieren und Fremdschlüssel für Referenz einführen. - 1:n-Beziehungen werden aufgelöst.
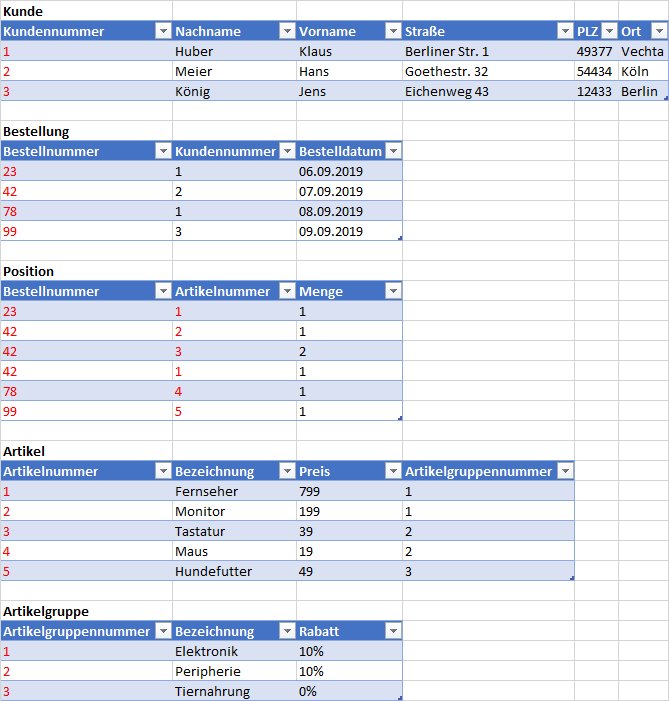
Ergebnis
- Jede Tabelle enthält genau ein Konzept.
- Keine Daten sind mehr redundant.
- In jeder Tabelle gibt es einen eindeutigen Primärschlüssel.
- Fremdschlüssel werden für Referenzen auf Datensätze in anderen Tabellen verwendet.
Literaturempfehlungen
Zum Einstieg ins Thema Datenbanken inkl. Modellierung, Normalisierung und SQL empfehle ich Einstieg in SQL* von Michael Laube.
") *
*







Hi
Wollte ich gerne als PDF habe ist das möglich?
Was möchtest du als PDF haben?
Danke für die Erklärung, Stefan! 🙂
Hallo Stefan
Danke für die schöne Aufteilung und Beschreibung von der 0. Normalform auf die 3. Normalform.
Was mich allerdings stört ist die Spalte Rabatt, der an den PK Artikelgruppe gekoppelt ist, also hat man automatisch 10% Rabatt, wenn man einen Artikel aus der Artikelgruppe Elektronik bzw. Peripherie bestellt?
Würde es da Sinn machen eine neue Tabelle Rabatt einzuführen?
Außerdem könnten auch bestimme Kunden (Mitarbeiter, Unternehmen) Rabatte bekommen?
Beste Grüße
Jonathan
Hallo Jonathan, je nach Datenmodell kann es sinnvoll sein, deine Ergänzungen durchzuführen. Aber das Beispiel ist natürlich einfach gewählt, um die Grundlagen zu erklären. Allerdings wäre eine Tabelle
Rabattwohl unsinnig, denn was soll darin stehen? Rabatt-ID 1, Rabatt-Satz 10%. Welche Felder sind hier sonst noch sinnvoll? Du kannst auch einfach die10als Wert für Rabatt in die Tabellen eintragen.Hello Stefen,
vielen lieben Dank für Ihre Mühe und die sehr gute Materialen.
Hiere habe ich eine Frage:
Warum brauchen wir die
Kundennummer-Attribute in 1. NF als Primärschlüssel?Meiner Meinung nach reicht es die
Bestellungsnummer&Artikelnummer, um einen Datensatz deutlich zu identifizieren.Noch einen Wunsch:
Schwierigkeiten habe ich immer bei der IHK-Aufgaben, den Primärschlüssel in 2.NF herauszufinden 🙁
z.B. eine Tabele besteht aus folgenden Spalten:
Bestell-Nr. Datum Lieferant Artikel Menge Einzelpreis
Was sollte der Primärschlüssel sein? Könnten Sie uns vielleicht einen Tip uns geben?
Vielen Dank nochmal
Hallo Diaa,
da hast du recht! Im Beispiel wäre ein Datensatz mit Bestellnummer und Artikelnummer bereits eindeutig identifiziert! Ich habe die Kundennummer nur dazugenommen, um zu zeigen, dass eigentlich drei „Dinge“ in einer Tabelle verwurstet werden.
Zu deinem Beispiel: Die gezeigte Tabelle ist nicht in der 2. Normalform! Bestellung/Artikel (und ggfs. Artikel/Lieferant) sind m:n-Beziehungen, die in der 2. NF bereits aufgelöst sein müssten. Daher hast du auch Schwierigkeiten, den Schlüssel zu bestimmen.
Ein Primärschlüssel, egal in welcher NF, muss minimal sein. Andernfalls könnte man theoretisch auch alle Spalten zusammen als Primärschlüssel markieren. Täte man dies in der 1. NF, hätte man zugleich die 2. und 3. NF erstellt – was aber zu völlig abstrusen Ergebnissen führen würde (im Sinne der Normalisierungsziele). Im obigen Bsp. muss, wie Diaa schrieb, als Primärschlüssel Bestellungsnummer&Artikelnummer bei der 1. NF gewählt werden. Dann lässt sich die 2. NF erzeugen, indem man sämtliche Attribute auslagert, die nur von einem Teil des Schlüssels abhängen.
In diesem Beispiel führt die Abweichungen von der Regel der Minimalität zu keinem Problem bei der Erstellung der 3. NF, da der Autor eine „intuitiv“ gute Wahl getroffen hat, ob das jedoch bei allen Anwendungsfällen gelingt, wage ich stark zu bezweifeln.
Hallo peter, danke für die Ergänzung!
Danke für den Beitrag. Gut, dass auch auf die unnormalisierte Ausgangssituation eingegangen wurde. Ich plane ein neues Datenbankmodell für mein eigenes Unternehmen, das besser strukturiert ist. Dafür muss ich mich noch an einen Ansprechpartner für IT-Consulting wenden.
Gern geschehen! 🙂
Hallo,
besteht nicht eine transitive Abhängigkeit zwischen Postleitzahl und Ort?
Nein. Dazwischen liegt eine m-zu-n-Beziehung vor. Der Ort folgt nicht aus der PLZ.